مدلسازی معادلات ساختاری (SEM)| مفاهیم، کاربردها، مزایا و محدودیتها

- 1 - مقدمه
- 2 - مدلسازی معادلات ساختاری (SEM) چیست؟
- 3 - SEM چه مسئلهای را حل میکند؟
- 4 - کاربرد SEM در مدیریت و مهندسی
- 5 - اجزای اصلی SEM
- 5-1 - متغیرهای پنهان
- 5-2 - متغیرهای مشاهدهپذیر
- 5-3 - مدل اندازهگیری
- 5-4 - مدل ساختاری در SEM
- 6 - مزایای مدلسازی معادلات ساختاری
- 7 - چالشهای استفاده از مدلسازی معادلات ساختاری
- 8 - نرمافزارهای رایج در SEM
- 9 - انواع رویکردهای مدلسازی معادلات ساختاری
- 9-1 - رویکرد مبتنی بر کوواریانس (CB‑SEM)
- 9-2 - رویکرد حداقل مربعات جزئی (PLS‑SEM)
- 10 - ترکیب SEM با سایر رویکردهای تحلیلی
- 10-1 - ترکیب SEM با ISM
- 10-2 - ترکیب SEM با یادگیری ماشین (مخصوصا شبکه عصبی مصنوعی)
- 10-3 - ترکیب SEM با سیستم استنتاج فازی عصبی (ANFIS)
- 11 - سؤالات متداول
مقدمه
در بسیاری از پژوهشهای مدیریتی، صنعتی و علوم رفتاری، پژوهشگر با مفاهیمی سروکار دارد که بهراحتی قابل اندازهگیری مستقیم نیستند. مفاهیمی مثل رضایت مشتری، کیفیت خدمات، نوآوری، فرهنگ سازمانی، عملکرد، تعهد سازمانی و مدیریت دانش معمولاً در قالب چند شاخص یا گویه سنجیده میشوند، نه با یک عدد ساده. از طرفی، روابط میان این مفاهیم نیز اغلب پیچیده، چندلایه و گاهی غیرمستقیم هستند. در چنین شرایطی، روشهای آماری ساده همیشه پاسخگو نیستند.
اینجاست که مدلسازی معادلات ساختاری یا SEM وارد میشود؛ روشی قدرتمند برای تحلیل همزمان روابط میان متغیرهای پنهان و متغیرهای مشاهدهپذیر. SEM به پژوهشگر کمک میکند نهتنها روابط مستقیم میان متغیرها را بررسی کند، بلکه اثرات غیرمستقیم، نقش متغیرهای میانجی و ساختار کلی مدل مفهومی را نیز بهصورت یکپارچه ارزیابی کند.
به بیان ساده، اگر بخواهیم بدانیم «چه چیزی بر چه چیزی اثر میگذارد و این اثر از چه مسیری منتقل میشود»، SEM یکی از مناسبترین ابزارهاست.
از همین رو، این روش در حوزههایی مانند مدیریت، علوم اجتماعی، مهندسی صنایع، بازاریابی، منابع انسانی و تحلیل رفتار مشتری کاربرد گستردهای پیدا کرده است. افزون بر این، در سالهای اخیر SEM وارد مرحلهای تازه شده و در ترکیب با روشهایی مانند ISM و حتی یادگیری ماشین نیز بهکار گرفته میشود؛ موضوعی که نشان میدهد این رویکرد هنوز هم زنده، پویا و روبهتوسعه است.
در ویدیوی زیر مفاهیم مدلسازی معادلا ساختاری به زبان خیلی ساده آموزش داده شده است. (در این ویدیو آموزشی یادخواهید گرفت چه وقت از معادلات ساختاری باید استفاده کرد، انواع متغیرها چه هستند، پرسشنامه چگونه می باشد. متغیر میانجی و تعدلگر چیست و…)
مدلسازی معادلات ساختاری (SEM) چیست؟
مدلسازی معادلات ساختاری یا Structural Equation Modeling یک روش آماری پیشرفته است که برای تحلیل همزمان روابط میان متغیرهای پنهان و مشاهدهپذیر بهکار میرود. در این روش، پژوهشگر میتواند مجموعهای از روابط علّی را در قالب یک مدل مفهومی مشخص کرده و سپس آن مدل را با دادههای واقعی آزمون کند.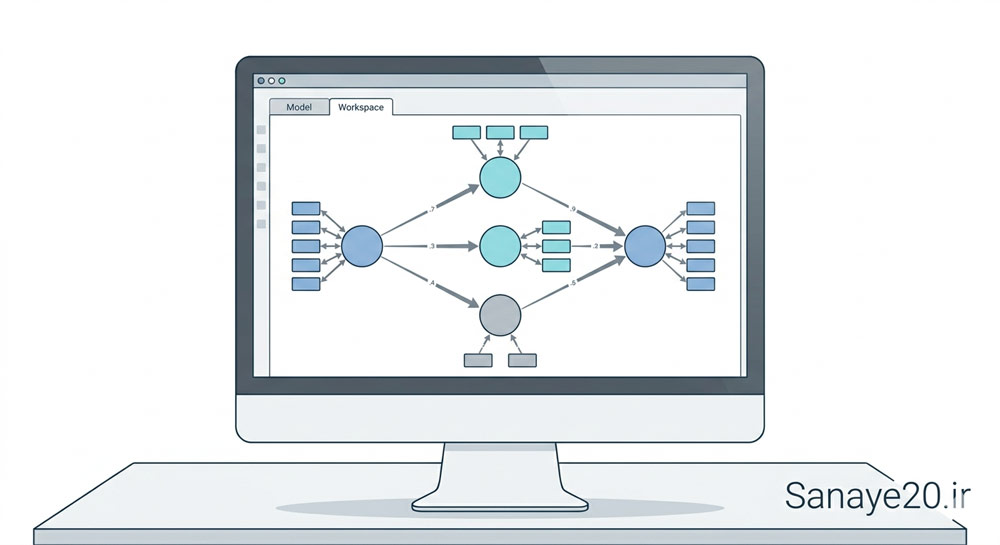
SEM در واقع ترکیبی از چند منطق آماری است، از جمله:
- تحلیل عاملی
- تحلیل مسیر
- مدلهای رگرسیونی
همین ترکیب باعث شده SEM نسبت به روشهای سنتی، انعطافپذیری و قدرت تحلیلی بیشتری داشته باشد. در رگرسیون معمولاً یک یا چند متغیر مستقل بر یک متغیر وابسته اثر میگذارند؛ اما در SEM میتوان چندین رابطه را بهصورت همزمان، در یک چارچوب یکپارچه بررسی کرد.
به همین دلیل، SEM زمانی بسیار مفید است که:
- متغیرها چندبعدی باشند،
- روابط پیچیده و چندلایه باشند،
- پژوهشگر بخواهد مدل نظری خود را همزمان ارزیابی کند،
- و اندازهگیری مستقیم برخی مفاهیم ممکن نباشد.
SEM چه مسئلهای را حل میکند؟
بسیاری از مسائل پژوهشی را نمیتوان با یک رابطه ساده و خطی توضیح داد. برای مثال، فرض کنید بخواهید بررسی کنید که:
- کیفیت خدمات چگونه بر رضایت مشتری اثر میگذارد،
- رضایت مشتری چگونه بر وفاداری اثر دارد،
- و در این میان نقش اعتماد یا تصویر ذهنی برند چیست.
در چنین حالتی، شما با چند رابطه همزمان سروکار دارید. علاوه بر آن، برخی متغیرها مانند «رضایت»، «اعتماد» یا «کیفیت ادراکشده» مستقیماً قابل اندازهگیری نیستند و باید از طریق چند سوال یا شاخص سنجیده شوند.
SEM دقیقاً برای حل چنین مسائلی طراحی شده است؛ یعنی:
- تحلیل روابط چندگانه
- مدیریت متغیرهای پنهان
- آزمون مدلهای نظری
- بررسی اثرات مستقیم و غیرمستقیم
به همین دلیل، این روش در پژوهشهای علوم انسانی و مدیریتی بسیار محبوب شده است.
کاربرد SEM در مدیریت و مهندسی
یکی از مهمترین کاربردهای مدلسازی معادلات ساختاری در مدیریت تحلیل روابط پیچیده بین عوامل مختلف سازمانی است.
- تحلیل رضایت مشتری: در تحقیقات بازاریابی از مدل معادلات ساختاری برای بررسی عوامل مؤثر بر رضایت مشتری استفاده میشود.
- مدیریت زنجیره تأمین: در حوزه مهندسی صنایع، SEM برای تحلیل روابط بین عوامل مختلف زنجیره تأمین استفاده میشود.
- مدیریت دانش: بسیاری از پژوهشگران از تحلیل SEM در مدیریت دانش برای بررسی رابطه بین اشتراک دانش و عملکرد سازمان استفاده میکنند.
اجزای اصلی SEM
برای اینکه SEM را درست درک کنیم، باید با اجزای اصلی آن آشنا شویم.
متغیرهای پنهان
متغیرهای پنهان یا Latent Variables مفاهیمی هستند که مستقیماً مشاهده نمیشوند، اما از طریق شاخصها یا گویهها سنجیده میشوند.
برای مثال:
- رضایت مشتری
- اعتماد سازمانی
- تعهد سازمانی
- فرهنگ سازمانی
- نوآوری سازمانی
برای اندازهگیری این متغیرها معمولاً از پرسشنامه استفاده میشود و هر متغیر پنهان با چندین سؤال یا شاخص اندازهگیری میشود.
متغیرهای مشاهدهپذیر
متغیرهای مشاهدهپذیر همان شاخصهایی هستند که پژوهشگر میتواند آنها را مستقیماً اندازهگیری کند. این متغیرها معمولاً پاسخهای افراد به سؤالات پرسشنامه هستند.
برای مثال اگر متغیر پنهان «رضایت مشتری» باشد، شاخصهای آن میتوانند شامل موارد زیر باشند:
- میزان رضایت از کیفیت محصول
- میزان رضایت از خدمات پس از فروش
- احتمال توصیه برند به دیگران
مدل اندازهگیری
مدل اندازهگیری رابطه بین متغیرهای پنهان و شاخصهای مشاهدهپذیر را مشخص میکند.
در این مرحله پژوهشگر بررسی میکند که آیا شاخصهای مورد استفاده واقعاً میتوانند متغیر پنهان مورد نظر را اندازهگیری کنند یا خیر.
ارزیابی مدل اندازهگیری
در ارزیابی مدل اندازهگیری چند شاخص مهم بررسی میشود.
آلفای کرونباخ: آلفای کرونباخ یکی از شاخصهای مهم برای بررسی پایایی ابزار اندازهگیری است. معمولاً مقدار بالاتر از 0.7 قابل قبول در نظر گرفته میشود.
پایایی ترکیبی: پایایی ترکیبی نشان میدهد که شاخصهای یک متغیر پنهان تا چه حد با یکدیگر همبستگی دارند.
روایی همگرا و واگرا: روایی همگرا نشان میدهد که شاخصهای مربوط به یک متغیر پنهان تا چه حد به یکدیگر نزدیک هستند. روایی واگرا نشان میدهد که متغیرهای مختلف مدل تا چه حد از یکدیگر متمایز هستند.
مدل ساختاری در SEM
مدل ساختاری روابط بین متغیرهای پنهان را نشان میدهد. این بخش در واقع همان مدل مفهومی پژوهش است. برای مثال در یک تحقیق ممکن است فرضیههای زیر بررسی شوند:
کیفیت خدمات ← رضایت مشتری
رضایت مشتری ← وفاداری مشتری
در این مرحله ضرایب مسیر بین متغیرها محاسبه میشوند.
شاخصهای ارزیابی مدل ساختاری
در تحلیل SEM با SmartPLS چند شاخص مهم برای ارزیابی مدل ساختاری وجود دارد.
- ضریب تعیین (R²): این شاخص نشان میدهد که چه مقدار از واریانس متغیر وابسته توسط متغیرهای مستقل توضیح داده میشود.
- اندازه اثر (f²): این شاخص میزان تأثیر هر متغیر مستقل بر متغیر وابسته را نشان میدهد.
- شاخص Q²: این شاخص برای بررسی قدرت پیشبینی مدل استفاده میشود.
مزایای مدلسازی معادلات ساختاری
SEM مزیتهای مهمی دارد که آن را از بسیاری از روشهای کلاسیک متمایز میکند:
- بررسی همزمان چند رابطه در یک مدل
- امکان تحلیل متغیرهای پنهان
- برآورد اثرات مستقیم و غیرمستقیم
- کاهش خطای اندازهگیری
- مناسب برای آزمون مدلهای نظری
- توان بالا در تحلیل روابط پیچیده
از این منظر، SEM فقط یک ابزار آماری نیست؛ بلکه یک چارچوب تحلیلی برای آزمون نظریه است.
چالشهای استفاده از مدلسازی معادلات ساختاری
مدلسازی معادلات ساختاری (Structural Equation Modeling یا SEM) یکی از روشهای پیشرفته تحلیل داده است که برای بررسی همزمان روابط میان متغیرهای آشکار و متغیرهای پنهان به کار میرود. این روش به پژوهشگران امکان میدهد مدلهای مفهومی پیچیده را بر اساس دادههای تجربی آزمون کنند و روابط علّی میان متغیرها را تحلیل نمایند. با وجود مزایای قابل توجه این روش در تحلیل دادههای مدیریتی و علوم اجتماعی، استفاده از مدل معادلات ساختاری با چالشها و محدودیتهایی نیز همراه است که در صورت عدم توجه به آنها ممکن است اعتبار نتایج پژوهش کاهش یابد. بنابراین آشنایی با این چالشها برای طراحی صحیح مدل و تفسیر دقیق نتایج ضروری است.
برخی از مهمترین چالشهای استفاده از مدلسازی معادلات ساختاری عبارتند از:
نیاز به دانش آماری:
مدلسازی معادلات ساختاری مبتنی بر مفاهیم پیشرفته آماری مانند تحلیل عاملی تأییدی، ماتریس کوواریانس، شاخصهای برازش مدل و ضرایب مسیر است. به همین دلیل پژوهشگر باید دانش مناسبی در زمینه آمار و روش تحقیق داشته باشد تا بتواند مدل را بهدرستی طراحی، اجرا و تفسیر کند.
طراحی صحیح مدل مفهومی:
پیش از اجرای مدل SEM لازم است یک چارچوب نظری و مدل مفهومی دقیق بر اساس ادبیات پژوهش طراحی شود. اگر روابط میان متغیرها یا ساختار متغیرهای پنهان بهدرستی تعریف نشود، نتایج تحلیل نمیتواند از نظر علمی معتبر باشد.
حجم نمونه مناسب:
یکی از پیشنیازهای مهم در مدلسازی معادلات ساختاری، برخورداری از حجم نمونه کافی است. در بسیاری از موارد، بهویژه در روشهای مبتنی بر کوواریانس، حجم نمونه پایین میتواند موجب کاهش قدرت آزمون آماری و بیثباتی ضرایب مدل شود.
تفسیر نتایج:
خروجی مدلهای SEM شامل شاخصهای متعددی مانند ضرایب مسیر، بارهای عاملی، شاخصهای برازش و مقادیر معنیداری است. تفسیر صحیح این شاخصها نیازمند درک دقیق مفاهیم آماری و ارتباط آنها با چارچوب نظری پژوهش است؛ در غیر این صورت ممکن است نتایج بهصورت نادرست گزارش شوند.
نرمافزارهای رایج در SEM
برخی از مهمترین نرمافزارهای مورد استفاده در مدلسازی معادلات ساختاری عبارتاند از:
- SmartPLS
- LISREL
- AMOS
هر یک از این نرمافزارها برای نوع خاصی از تحلیلهای SEM طراحی شدهاند و بسته به هدف پژوهش، حجم نمونه، نوع دادهها و رویکرد تحقیق مورد استفاده قرار میگیرند. برای مثال، SmartPLS بیشتر در رویکرد PLS-SEM و مطالعات پیشبینانه کاربرد دارد، در حالی که LISREL و AMOS عمدتاً در تحلیلهای مبتنی بر کوواریانس (CB-SEM) و آزمون مدلهای نظری استفاده میشوند.
در میان این نرمافزارها، SmartPLS به دلیل محیط کاربرپسند و انعطافپذیری بالا در سالهای اخیر محبوبیت زیادی پیدا کرده است. از سوی دیگر، LISREL و AMOS همچنان از ابزارهای مهم و معتبر در تحقیقات دانشگاهی و مدلهای نظری محسوب میشوند.
در مقالات آینده، هر یک از این نرمافزارها، کاربردها، تفاوتها، مزایا و نحوه انتخاب مناسبترین گزینه برای پژوهش بهصورت کامل و تخصصی بررسی خواهند شد.
انواع رویکردهای مدلسازی معادلات ساختاری
مدلسازی معادلات ساختاری یا Structural Equation Modeling (SEM) یکی از قویترین روشهای آماری در تحقیقهای مدیریتی، علوم اجتماعی و مهندسی صنایع است.
این روش به پژوهشگر کمک میکند تا ارتباط بین چندین متغیر پنهان (مثل رضایت مشتری یا اعتماد سازمانی) را بهصورت همزمان بررسی کند و بفهمد که کدام عامل بر دیگری تأثیر بیشتری دارد.
برای اجرای SEM، دو رویکرد اصلی وجود دارد که انتخاب هرکدام به هدف تحقیق، نوع داده و شرایط نمونه وابسته است:
رویکرد مبتنی بر کوواریانس (CB‑SEM)
در این روش که به آن Covariance-Based SEM هم گفته میشود، هدف اصلی بررسی این است که آیا مدل نظری پیشنهادی با دادههای واقعی سازگار است یا نه. یعنی پژوهشگر ابتدا یک مدل مفهومی بر اساس نظریه و پیشفرض علمی میسازد، سپس با دادههای واقعی بررسی میکند که مدل، معتبر و قابل تأیید هست یا خیر.
بهعبارت ساده، این روش بیشتر برای آزمون نظریهها و مدلهای تأییدی (Confirmatory Research) مناسب است. CB‑SEM مانند یک «تست انطباق تئوری با واقعیت» عمل میکند.
ویژگیهای اصلی CB‑SEM:
- تمرکز اصلی بر «برازش مدل نظری» با دادههاست.
- نیاز به حجم نمونه نسبتاً زیاد دارد تا نتایج پایدار و دقیق باشد.
- دادهها باید توزیع نرمال (Normal Distribution) داشته باشند.
- خروجی تحلیل شامل شاخصهای برازش مدل مانند CFI، RMSEA و GFI است.
نرمافزارهای رایج برای اجرای این روش:
- AMOS
- LISREL
مثال ساده:
فرض کنید یک محقق میخواهد بررسی کند آیا رضایت مشتری میتواند میانجی رابطه بین کیفیت خدمات و وفاداری مشتری باشد یا نه.
در این مدل، پژوهشگر براساس نظریات بازاریابی، چنین رابطهای را از قبل در ذهن دارد و حالا میخواهد ببیند آیا دادههای واقعی هم همین ساختار را تأیید میکنند.
این دقیقاً کاری است که CB‑SEM برایش مناسب است: تست نظریههای از پیش تعریفشده.
رویکرد حداقل مربعات جزئی (PLS‑SEM)
رویکرد Partial Least Squares SEM رویکردی جدیدتر، انعطافپذیرتر و بهنوعی کاربردیتر از CB‑SEM است. در این روش تمرکز بهجای آزمون برازش نظری، بر روی پیشبینی متغیرهای وابسته و تحلیل مسیرهای علی بین متغیرها قرار دارد. به همین دلیل PLS‑SEM هم در تحقیقات دانشگاهی جدید و هم در پژوهشهای سازمانی و بازاریابی بسیار محبوب شده است.
ویژگیهای اصلی PLS‑SEM:
- تمرکز اصلی بر پیشبینی و تبیین واریانس متغیرهای وابسته است.
- با دادههای غیرنرمال نیز میتواند کار کند.
- برای مدلهای پیچیده یا زمانی که نمونه آماری کوچک است، عالی عمل میکند.
- به شاخصهای برازش کلی وابسته نیست، بلکه قدرت تبیین و مسیرهای آماری را بررسی میکند.
نرمافزار اصلی:
نرمافزار SmartPLS محبوبترین ابزار برای اجرای این روش است. کار با آن بسیار ساده و گرافیکی است و خروجیهای تحلیلی دقیقی تولید میکند؛ به همین دلیل امروزه بسیاری از پژوهشگران در حال یادگیری و استفاده از آن هستند. آخرین نسخه این نرم افزار را می توان از سایت آن به نشانی https://smartpls.com دانلود کرد.
مثال ساده:
فرض کنید یک مدیر میخواهد بفهمد چه عواملی بیشتر از همه بر عملکرد کارکنان در یک شرکت تأثیر میگذارند. او دادههایی از متغیرهایی مثل انگیزه شغلی، آموزش، رضایت، و محیط کاری جمعآوری کرده و میخواهد بداند کدامیک بیشترین تأثیر را دارند. در این شرایط، چون هدف پیشبینی و تحلیل روابط علی است، روش PLS‑SEM مناسبتر رایجتر از CB‑SEM خواهد بود، بهخصوص اگر تعداد نمونهها کم یا دادهها غیرنرمال باشند.
در جدول زیر مقایسه ای بین رویکرد CB و PLS آورده شده است.
نکته مهم
در پژوهشهای فرضیهمحور، معمولاً هم میتوان از رویکرد PLS-SEM (مانند SmartPLS) و هم از رویکرد CB-SEM (مانند AMOS و LISREL) استفاده کرد. انتخاب بین این دو به عواملی مانند هدف پژوهش (تأیید نظریه یا پیشبینی)، حجم نمونه، نرمال بودن دادهها، پیچیدگی مدل و نوع سازهها بستگی دارد. بهطور کلی، CB-SEM بیشتر برای آزمون و تأیید نظریه و PLS-SEM بیشتر برای تحلیلهای پیشبینانه و مدلهای پیچیده بهکار میرود.
ترکیب SEM با سایر رویکردهای تحلیلی
در سالهای اخیر، مدلسازی معادلات ساختاری (SEM) علاوه بر کاربرد مستقل، با روشهای تحلیلی دیگری مانند ISM و یادگیری ماشین نیز ترکیب شده است. این رویکردهای ترکیبی به پژوهشگران کمک میکنند تا علاوه بر تحلیل روابط علّی و مفهومی، ساختار سلسلهمراتبی متغیرها و قدرت پیشبینی مدلها را نیز بهصورت دقیقتر بررسی کنند.
-
ترکیب SEM با ISM
یکی از رویکردهای نوین در پژوهشهای مدیریتی، ترکیب SEM با روش ISM (از روشهای تصمیم گیری چند معیاره می باشد) است. در این رویکرد:
- ابتدا ISM برای استخراج ساختار مفهومی روابط از دید خبرگان استفاده میشود،
- سپس SEM برای آزمون تجربی این روابط بهکار میرود.
این ترکیب مزایای مهمی دارد:
- افزایش اعتبار مدل مفهومی،
- ترکیب دانش خبرگان با تحلیل آماری،
- و کاهش خطا در طراحی مدل پژوهش.
به بیان ساده، ISM ساختار روابط را مشخص میکند و SEM اعتبار آماری آن را بررسی میکند.
پیشنهاد مطالعه: جهت مطالعه بیشتر این حالت، پست روش ism-sem را مطالعه کنید. -
ترکیب SEM با یادگیری ماشین (مخصوصا شبکه عصبی مصنوعی)
در سالهای اخیر، پژوهشگران بهسمت ترکیب SEM و الگوریتمهای یادگیری ماشین حرکت کردهاند. دلیل این موضوع آن است که:
- SEM در تبیین نظری بسیار قدرتمند است،
- اما یادگیری ماشین در پیشبینی و کشف الگو عملکرد فوقالعادهای دارد.
ترکیب این دو رویکرد میتواند:
- قدرت پیشبینی مدل را افزایش دهد،
- روابط پیچیدهتر را شناسایی کند،
- و تحلیلهای هوشمندانهتری ایجاد کند.
این حوزه یکی از روندهای آیندهدار در تحلیل دادههای مدیریتی و صنعتی محسوب میشود.
ترکیب SEM با سیستم استنتاج فازی عصبی (ANFIS)
در برخی پژوهشهای پیشرفته، از ترکیب مدلسازی معادلات ساختاری (SEM) با سیستم استنتاج فازی عصبی (ANFIS) استفاده میشود تا علاوه بر تحلیل روابط علّی بین متغیرها، قابلیت پیشبینی مدل نیز تقویت شود.
دلیل اهمیت این ترکیب آن است که:
- SEM در تبیین روابط مفهومی و آزمون فرضیهها عملکرد قدرتمندی دارد،
- اما ANFIS بهصورت همزمان از قابلیتهای «شبکه عصبی مصنوعی» و «منطق فازی» بهره میبرد.
در این رویکرد شبکه عصبی مصنوعی توانایی یادگیری الگوهای پیچیده از دادهها را فراهم میکند، و منطق فازی امکان مدلسازی ابهام، عدم قطعیت و قضاوتهای انسانی را ایجاد میکند.
برای مطالعه بیشتر در رابطه با این نوع ترکیب مقاله سیستم استنتاج فازی عصبی (ANFIS) را مطالعه کنید.